Ces dernières semaines, on a beaucoup parlé d’intelligence artificielle, avec les algorithmes génétiques et les réseaux neuronnaux, on avait par ailleurs vu que ces derniers pouvaient être couplés. Aujourd’hui, on va voir un autre moyen de faire apprendre un réseau neuronnal : la méthode par convolution.
Un peu d'histoire


Utilisation et fonctionnement

Un exemple concret d'application
-
 Un casque VR compatible unity à construire soi-même pour moins de 100€ : Relativ
Un casque VR compatible unity à construire soi-même pour moins de 100€ : Relativ
Aujourd'hui, le BlogDuWebdesign vous propose un article un peu spécial ! En effet, il ... -
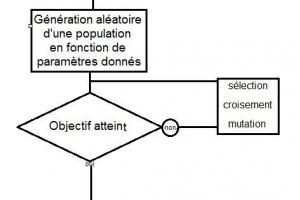 Les algorithmes génétiques: une solution d’avenir ?
Les algorithmes génétiques: une solution d’avenir ?
Aujourd’hui sur le blog du webdesign, on va s’intéresser au concept d’algor...